Technology Snapshots & Observed Characteristics
Neural Style Transfer (NST): Artistic Blending
- Observed Output: Successfully merges content from one image with the style of another, allowing unique artistic control.
- Key Observations: Requires distinct source images and involves an iterative optimization process. Suggests utility for specific artistic branding elements.
Generative Adversarial Networks (GANs)
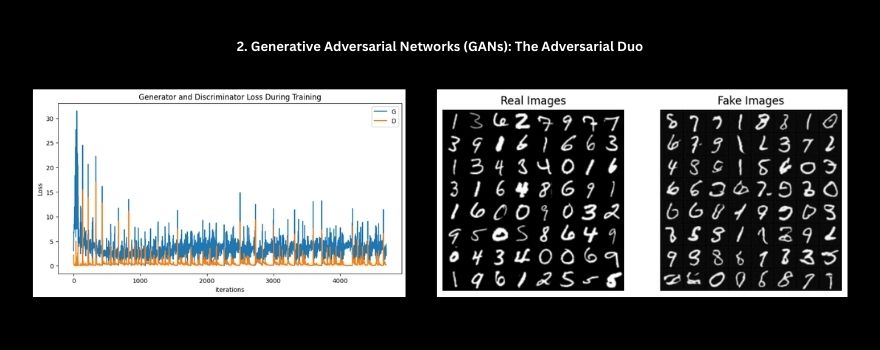
- Observed Output: Capable of synthesizing novel images from latent noise.
- Key Observations: Training presented challenges with stability (e.g., mode collapse observed in basic DCGAN). Custom builds appear resource-intensive.
Variational Autoencoders (VAEs): Learning Data Representations
- Observed Output: Demonstrated reconstruction of custom datasets (e.g., smiley faces) and generation of simple variations. Training was notably stable.
- Key Observations: Outputs tended to be softer than some other methods. Appears useful for understanding data variations or conceptual work.
Diffusion Models (Stable Diffusion): Current Standard for High Fidelity
- Observed Output: Using pre-trained Stable Diffusion models (v1.4, v2.1-base, v2.1) yielded high-fidelity, diverse images directly from text prompts, showcasing strong control.
- Key Observations: Pre-trained models offer significant capabilities out-of-the-box. This approach stands out for a broad range of applications.
Comparative Landscape
Based on this exploration, certain patterns emerged regarding key factors:
Cost & Accessibility:
- Diffusion models accessed via SaaS/API platforms appear to have the lowest barrier to entry (e.g., monthly subscriptions observed around $10-$60).
- Open-source diffusion models offer free model access but require user-managed setup and GPU resources.
- Developing custom NST, GAN, or VAE solutions from scratch would entail higher development costs.
Speed & Scalability:
SaaS/API-based diffusion tools demonstrated rapid image generation and appear well-suited for scalable content needs.
Other explored methods (NST, custom GAN/VAE training) were less inherently suited for rapid, diverse, on-demand generation.
Output Quality & Control:
- Diffusion models consistently produced the highest observed quality and offered significant control via text prompting.
- The quality from other methods was more variable and often application-specific.
Usage Rights & Licensing:
- The landscape is varied. SaaS tools typically define commercial use in their terms of service.
- Open-source models often have permissive licenses (e.g., Stable Diffusion’s CreativeML Open RAIL-M), though the user bears responsibility for the content generated.